Elasticsearch, Logstash ve Kibana (Elastic Stack) Ubuntu 18.04’e Nasıl Yüklenir
Giriş
Daha önce ELK Yığını olarak bilinen Elastic Stack , Elastic tarafından üretilen ve herhangi bir biçimde herhangi bir kaynaktan oluşturulan günlükleri aramanıza, analiz etmenize ve görselleştirmenize olanak tanıyan, merkezi günlük kaydı olarak bilinen bir uygulama olan açık kaynaklı bir yazılım koleksiyonudur . Merkezi günlük kaydı, sunucularınız veya uygulamalarınızla ilgili sorunları belirlemeye çalışırken çok yararlı olabilir, çünkü tüm günlüklerinizi tek bir yerde aramanıza izin verir. Ayrıca, belirli bir zaman dilimi boyunca günlüklerini ilişkilendirerek birden çok sunucuya yayılan sorunları tanımlamanıza izin verdiği için de kullanışlıdır.
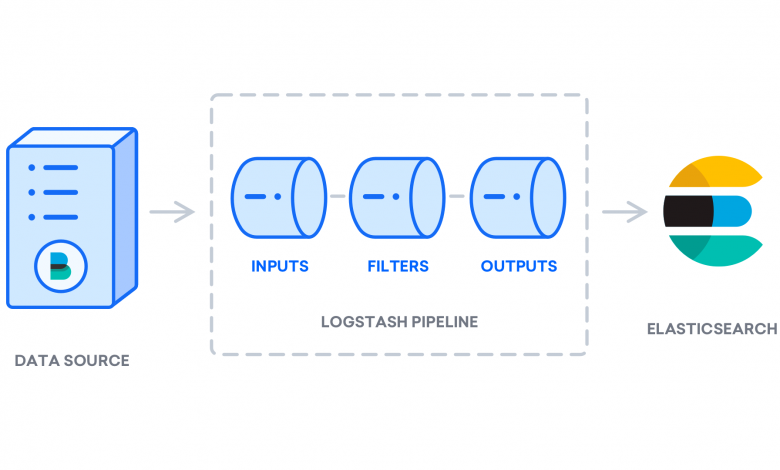
Elastic Stack’in dört ana bileşeni vardır:
- Elasticsearch :toplanan tüm verileri depolayandağıtılmış bir RESTful arama motoru.
- Logstash : Elasticsearch’e gelen verileri gönderen Elastic Stack’ın veri işleme bileşeni.
- Kibana : günlükleri aramak ve görselleştirmek için bir web arayüzü.
- Beats : yüzlerce veya binlerce makineden Logstash veya Elasticsearch’e veri gönderebilen hafif, tek amaçlı veri taşıyıcıları.
Bu eğitimde Elastic Stack’i bir Ubuntu 18.04 sunucusuna kuracaksınız. Günlükleri ve dosyaları iletmek ve merkezileştirmek için kullanılan bir Beat olan Filebeat de dahil olmak üzere Elastic Stack’in tüm bileşenlerini nasıl kuracağınızı ve bunları sistem günlüklerini toplamak ve görselleştirmek için nasıl yapılandıracağınızı öğreneceksiniz . Ek olarak, Kibana normalde yalnızca üzerinde mevcut olduğundan localhost, bir web tarayıcısı üzerinden erişilebilir olması için onu proxy yapmak için Nginx kullanacağız . Tüm bu bileşenleri, Elastic Stack sunucumuz olarak adlandıracağımız tek bir sunucuya kuracağız .
Not : Elastic Stack’i kurarken, tüm yığında aynı sürümü kullanmanız gerekir. Bu eğitimde, bu yazının yazıldığı sırada Elasticsearch 7.6.1, Kibana 7.6.1, Logstash 7.6.1 ve Filebeat 7.6.1 olan tüm yığının en son sürümlerini kuracağız.
Önkoşullar
Bu öğreticiyi tamamlamak için aşağıdakilere ihtiyacınız olacak:
- Bir Ubuntu 18.04 sunucunuzu sudo ayrıcalıklarına sahip bir kök olmayan kullanıcı ve yapılandırılmış bir güvenlik duvarı da dahil olmak üzere,
ufw. Elastic Stack sunucunuzun ihtiyaç duyacağı CPU, RAM ve depolama miktarı, toplamayı düşündüğünüz günlüklerin hacmine bağlıdır. Bu eğitimde, Elastic Stack sunucumuz için aşağıdaki özelliklere sahip bir VPS kullanacağız:- İşletim Sistemi: Ubuntu 18.04
- RAM: 4 GB
- İşlemci: 2
- Elasticsearch ve Logstash için gerekli olan Java 8, sunucunuzda yüklüdür. Java 9’un desteklenmediğini unutmayın.
- Nginx, bu kılavuzda daha sonra Kibana için bir ters proxy olarak yapılandıracağımız sunucunuza kuruldu.
- Tam nitelikli bir alan adı (FQDN). Bu eğitim
example.comboyunca kullanılacak. Sen bir alan adı satın alabilirsiniz namecheap , ücretsiz olarak almak Freenom veya seçtiğiniz alan adı kayıt kullanın. - Aşağıdaki DNS kayıtlarının her ikisi de sunucunuz için ayarlandı.
example.comSunucunuzun genel IP adresini gösteren bir A kaydı .- Sunucunuzun genel IP adresini gösteren bir A kaydı .
www.example.com,
Varsayılan JRE / JDK’yı Yükleme
Java’yı yüklemek için en kolay seçenek, Ubuntu ile paketlenmiş sürümü kullanmaktır. Varsayılan olarak, Ubuntu 18.04, JRE ve JDK’nın açık kaynaklı bir çeşidi olan OpenJDK sürüm 11’i içerir.
Bu sürümü yüklemek için önce paket dizinini güncelleyin:
sudo apt updateArdından, Java’nın zaten yüklü olup olmadığını kontrol edin:
java -versionJava şu anda yüklü değilse, aşağıdaki çıktıyı görürsünüz:
Output
Command 'java' not found, but can be installed with:
apt install default-jre
apt install openjdk-11-jre-headless
apt install openjdk-8-jre-headlessJRE’yi OpenJDK 11’den yükleyecek olan varsayılan Java Runtime Environment’ı (JRE) yüklemek için aşağıdaki komutu yürütün:
sudo apt install default-jre
JRE, neredeyse tüm Java yazılımlarını çalıştırmanıza izin verecektir.
Kurulumu şununla doğrulayın:
java -versionAşağıdaki çıktıyı göreceksiniz:
Output
openjdk version "11.0.7" 2020-04-14
OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-2ubuntu218.04)
OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-2ubuntu218.04, mixed mode, sharing)Bazı özel Java tabanlı yazılımları derlemek ve çalıştırmak için JRE’ye ek olarak Java Geliştirme Kitine (JDK) ihtiyacınız olabilir. JDK’yı yüklemek için, JRE’yi de yükleyecek olan aşağıdaki komutu yürütün:
sudo apt install default-jdk javacJava derleyicisinin sürümünü kontrol ederek JDK’nın kurulu olduğunu doğrulayın :
javac -versionAşağıdaki çıktıyı göreceksiniz:
Output
javac 11.0.7Şimdi Oracle’ın resmi JDK ve JRE’sinin nasıl kurulacağına bakalım.
Oracle JDK 11’i Yükleme
Oracle’ın Java için lisans sözleşmesi, paket yöneticileri aracılığıyla otomatik yüklemeye izin vermez. Oracle tarafından dağıtılan resmi sürüm olan Oracle JDK’yı kurmak için, bir Oracle hesabı oluşturmanız ve kullanmak istediğiniz sürüm için yeni bir paket deposu eklemek üzere JDK’yı manuel olarak indirmeniz gerekir. Ardından, üçüncü taraf bir kurulum komut dosyasınınapt yardımıyla yüklemek için kullanabilirsiniz .
İndirmeniz gereken Oracle JDK sürümü, yükleyici komut dosyasının sürümüyle eşleşmelidir. Hangi sürüme ihtiyacınız olduğunu öğrenmek için oracle-java11-installersayfayı ziyaret edin .
Aşağıdaki şekilde gösterildiği gibi Bionic paketini bulun :
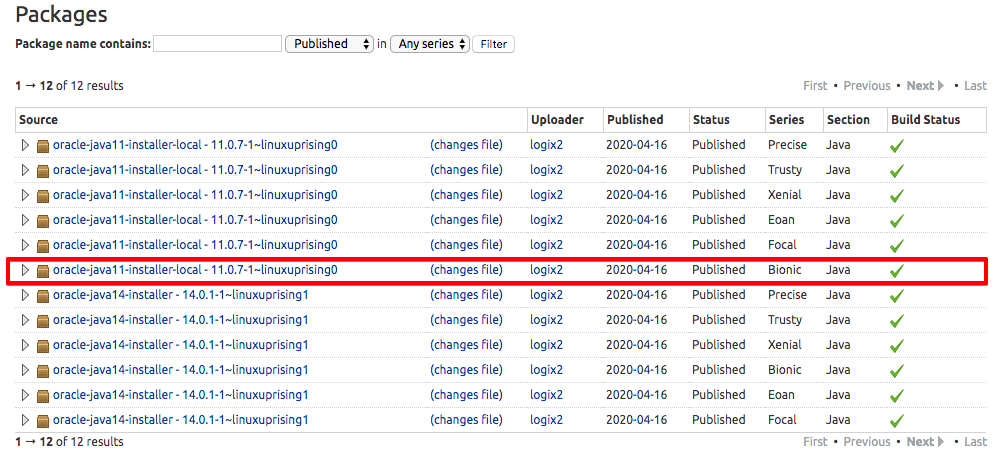
Bu görselde komut dosyasının sürümü 11.0.7. Bu durumda Oracle JDK 11.0.7’ye ihtiyacınız olacak. Bu sayfadan herhangi bir şey indirmenize gerek yok; kurulum komut dosyasını aptkısaca indireceksiniz .
Ardından İndirilenler sayfasını ziyaret edin ve ihtiyacınız olanla eşleşen sürümü bulun.

Click JDK İndir butonuna ve gösteriler o versiyonları mevcuttur bir ekrana yönlendirilirsiniz. .tar.gzLinux paketine tıklayın .
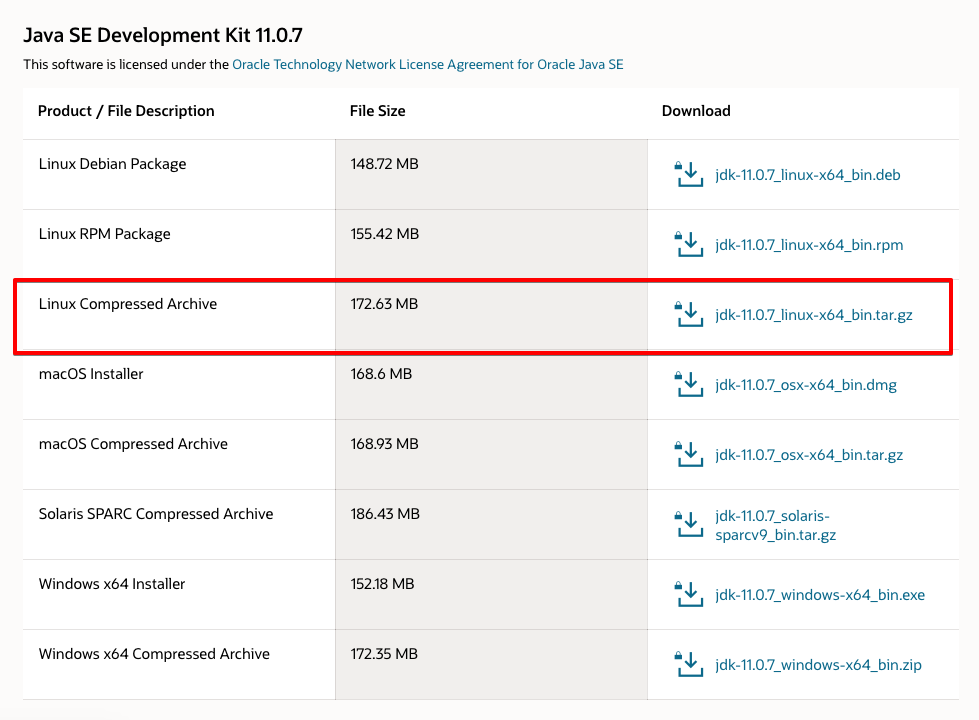
Oracle lisans sözleşmesini kabul etmenizi isteyen bir ekran ile karşılaşacaksınız. Lisans sözleşmesini kabul etmek için onay kutusunu seçin ve İndir düğmesine basın . İndirmeniz başlayacak. İndirme başlamadan önce Oracle hesabınızda bir kez daha oturum açmanız gerekebilir.
Dosya indirildikten sonra, onu sunucunuza aktarmanız gerekir. Yerel makinenizde, dosyayı sunucunuza yükleyin. MacOS kullanan Linux veya Windows Linux, Windows Subsystem kullanmak scpsizin ev dizinine dosya aktarmak için komutu users kullanıcı. Aşağıdaki komut, Oracle JDK dosyasını yerel makinenizin Downloadsklasörüne kaydettiğinizi varsayar :
scp Downloads/jdk-11.0.7_linux-x64_bin.tar.gz users@your_server_ip:~Dosya yüklemesi tamamlandığında, sunucunuza geri dönün ve Oracle’ın Java’sını yüklemenize yardımcı olacak üçüncü taraf havuzunu ekleyin.
Sisteminize komutu software-properties-commonekleyen paketi kurun add-apt-repository:
sudo apt install software-properties-commonArdından, yüklemek üzere olduğunuz yazılımı doğrulamak için kullanılan imzalama anahtarını içe aktarın:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys EA8CACC073C3DB2ABu çıktıyı göreceksiniz:
Output
gpg: key EA8CACC073C3DB2A: public key "Launchpad PPA for Linux Uprising" imported
gpg: Total number processed: 1
gpg: imported: 1Ardından add-apt-repositorydepoyu paket kaynakları listenize eklemek için komutu kullanın:
sudo add-apt-repository ppa:linuxuprising/javaBu mesajı göreceksiniz:
Output
Oracle Java 11 (LTS) and 12 installer for Ubuntu, Linux Mint and Debian.
Java binaries are not hosted in this PPA due to licensing. The packages in this PPA download and install Oracle Java 11, so a working Internet connection is required.
The packages in this PPA are based on the WebUpd8 Oracle Java PPA packages: https://launchpad.net/~webupd8team/+archive/ubuntu/java
Created for users of https://www.linuxuprising.com/
Installation instructions (with some tips), feedback, suggestions, bug reports etc.:
. . .
Press [ENTER] to continue or ctrl-c to cancel adding itENTERKuruluma devam etmek için düğmesine basın . Hakkında bir mesaj görebilirsiniz no valid OpenPGP data found, ancak bunu güvenle göz ardı edebilirsiniz.
Yeni yazılımı kuruluma hazır hale getirmek için paket listenizi güncelleyin:
sudo apt update Yükleyici, indirdiğiniz Oracle JDK’yi arayacaktır /var/cache/oracle-jdk11-installer-local. Bu dizini oluşturun ve Oracle JDK arşivini oraya taşıyın:
sudo mkdir -p /var/cache/oracle-jdk11-installer-local/
sudo cp jdk-11.0.7_linux-x64_bin.tar.gz /var/cache/oracle-jdk11-installer-local/Son olarak paketi kurun:
sudo apt install oracle-java11-installer-localYükleyici önce sizden Oracle lisans sözleşmesini kabul etmenizi isteyecektir. Sözleşmeyi kabul edin, ardından yükleyici Java paketini çıkaracak ve yükleyecektir.
Adım 1 – Nginx’i Kurmak
Nginx, Ubuntu’nun varsayılan depolarında mevcut olduğundan, aptpaketleme sistemini kullanarak bu depolardan yüklemek mümkündür .
Bu, aptbu oturumdaki paketleme sistemiyle ilk etkileşimimiz olduğundan, en son paket listelerine erişebilmemiz için yerel paket dizinimizi güncelleyeceğiz. Daha sonra şunları yükleyebiliriz nginx:
sudo apt update
sudo apt install nginx Prosedürü kabul ettikten sonra, aptNginx’i ve gerekli tüm bağımlılıkları sunucunuza kuracaktır.
Adım 2 – Güvenlik Duvarını Ayarlama
Nginx’i test etmeden önce, hizmete erişime izin vermek için güvenlik duvarı yazılımının ayarlanması gerekir. Nginx ufw, kurulumdan sonra kendisini bir hizmet olarak kaydeder ve Nginx erişimine izin vermeyi kolaylaştırır.
ufwNasıl çalışılacağını bilen uygulama yapılandırmalarını yazarak listeleyin :
sudo ufw app listUygulama profillerinin bir listesini almalısınız:
Output
Available applications:
Nginx Full
Nginx HTTP
Nginx HTTPS
OpenSSHGördüğünüz gibi, Nginx için kullanılabilen üç profil vardır:
- Nginx Full : Bu profil hem 80 numaralı bağlantı noktasını (normal, şifrelenmemiş web trafiği) hem de 443 numaralı bağlantı noktasını (TLS / SSL şifreli trafik) açar
- Nginx HTTP : Bu profil yalnızca 80 numaralı bağlantı noktasını açar (normal, şifrelenmemiş web trafiği)
- Nginx HTTPS : Bu profil yalnızca 443 numaralı bağlantı noktasını açar (TLS / SSL şifreli trafik)
Yapılandırdığınız trafiğe yine de izin verecek en kısıtlayıcı profili etkinleştirmeniz önerilir. Henüz bu kılavuzda sunucumuz için SSL yapılandırmadığımızdan, yalnızca 80 numaralı bağlantı noktasında trafiğe izin vermemiz gerekecek.
Bunu yazarak etkinleştirebilirsiniz:
sudo ufw allow 'Nginx HTTP'Değişikliği yazarak doğrulayabilirsiniz:
sudo ufw status
Görüntülenen çıktıda izin verilen HTTP trafiğini görmelisiniz:
Output
Status: active
To Action From
-- ------ ----
OpenSSH ALLOW Anywhere
Nginx HTTP ALLOW Anywhere
OpenSSH (v6) ALLOW Anywhere (v6)
Nginx HTTP (v6) ALLOW Anywhere (v6)Adım 1 – Elasticsearch Kurulumu ve Yapılandırılması
Elastic Stack bileşenleri Ubuntu’nun varsayılan paket depolarında mevcut değildir. Bununla birlikte, Elastic’in paket kaynak listesi eklendikten sonra APT ile kurulabilirler.
Elastic Stack’in tüm paketleri, sisteminizi paket sahtekarlığından korumak için Elasticsearch imzalama anahtarı ile imzalanmıştır. Anahtar kullanılarak kimliği doğrulanan paketler, paket yöneticiniz tarafından güvenilir olarak kabul edilecektir. Bu adımda, Elasticsearch’ü kurmak için Elasticsearch genel GPG anahtarını içe aktaracak ve Elastic paket kaynak listesini ekleyeceksiniz.
Başlamak için, Elasticsearch genel GPG anahtarını APT’ye aktarmak için aşağıdaki komutu çalıştırın:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Ardından, Esnek kaynak listesini sources.list.d, APT’nin yeni kaynakları arayacağı dizine ekleyin :
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Ardından, APT’nin yeni Elastic kaynağını okuyabilmesi için paket listelerinizi güncelleyin:
sudo apt update
Sonra Elasticsearch’ü şu komutla kurun:
sudo apt install elasticsearch
Elasticsearch kurulumu tamamlandığında, Elasticsearch’ün ana yapılandırma dosyasını düzenlemek için tercih ettiğiniz metin düzenleyiciyi kullanın elasticsearch.yml. Burada kullanacağız nano:
sudo nano /etc/elasticsearch/elasticsearch.yml
Not: Elasticsearch’ün konfigürasyon dosyası YAML formatındadır, bu da girintinin çok önemli olduğu anlamına gelir! Bu dosyayı düzenlerken fazladan boşluk eklemediğinizden emin olun.
Elasticsearch, limandaki her yerden gelen trafiği dinler 9200. Yabancıların verilerinizi okumasını veya REST API aracılığıyla Elasticsearch kümenizi kapatmasını önlemek için Elasticsearch örneğinize dışarıdan erişimi kısıtlamak isteyeceksiniz. network.hostBelirten satırı bulun , açıklamasını kaldırın ve değerini localhostşu şekilde görünecek şekilde değiştirin : /etc/elasticsearch/elasticsearch.yml
. . .
network.host: localhost
. . .Tuşuna elasticsearch.ymlbasıp CTRL+X, ardından Yve ardından ENTERkullanıyorsanız , kaydedip kapatın nano. Ardından, Elasticsearch hizmetini şu şekilde başlatın systemctl:
sudo systemctl start elasticsearch
Ardından, Elasticsearch’ün sunucunuz her önyüklendiğinde başlamasını sağlamak için aşağıdaki komutu çalıştırın:
sudo systemctl enable elasticsearch
Elasticsearch hizmetinizin çalışıp çalışmadığını bir HTTP isteği göndererek test edebilirsiniz:
curl -X GET "localhost:9200"
Şuna benzer yerel düğümünüz hakkında bazı temel bilgileri gösteren bir yanıt göreceksiniz:
Output
{
"name" : "ElasticSearch",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "SMYhVWRiTwS1dF0pQ-h7SQ",
"version" : {
"number" : "7.6.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "aa751e09be0a5072e8570670309b1f12348f023b",
"build_date" : "2020-02-29T00:15:25.529771Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}Artık Elasticsearch çalışmaya başladığına göre, Elastic Stack’in bir sonraki bileşeni olan Kibana’yı kuralım.
Adım 2 – Kibana Dashboard’u Kurma ve Yapılandırma
Göre resmi belgeler , sadece Elasticsearch yükledikten sonra Kibana yüklemelisiniz. Bu sırayla kurulum, her ürünün bağlı olduğu bileşenlerin doğru şekilde yerinde olmasını sağlar.
Önceki adımda Elastic paket kaynağını zaten eklediğiniz için, Elastic Stack’in kalan bileşenlerini aşağıdakileri kullanarak kurabilirsiniz apt:
sudo apt install kibanaArdından Kibana hizmetini etkinleştirin ve başlatın:
sudo systemctl enable kibana
sudo systemctl start kibana Kibana yalnızca dinleyecek şekilde yapılandırıldığından localhost, ona harici erişime izin vermek için bir ters proxy kurmalıyız . Bu amaçla sunucunuza zaten kurulu olması gereken Nginx’i kullanacağız.
İlk olarak, opensslKibana web arayüzüne erişmek için kullanacağınız bir yönetici Kibana kullanıcısı oluşturmak için komutu kullanın. Örnek olarak bu hesabı adlandıracağız kibanaadmin, ancak daha fazla güvenlik sağlamak için kullanıcınız için tahmin edilmesi zor olan standart olmayan bir ad seçmenizi öneririz.
Aşağıdaki komut, yönetici Kibana kullanıcısını ve şifresini oluşturacak ve bunları htpasswd.usersdosyada saklayacaktır . Nginx’i bu kullanıcı adı ve parolayı gerektirecek şekilde yapılandıracak ve bu dosyayı anlık olarak okuyacaksınız:
echo "kibanaadmin:`openssl passwd -apr1`" | sudo tee -a /etc/nginx/htpasswd.users
İstendiğinde bir şifre girin ve onaylayın. Kibana web arayüzüne erişmek için ihtiyacınız olacağından bu girişi hatırlayın veya not alın.
Ardından, bir Nginx sunucu blok dosyası oluşturacağız. Örnek olarak bu dosyaya şu şekilde atıfta bulunacağız example.com, ancak sizinkine daha açıklayıcı bir ad vermeniz yararlı olabilir. Örneğin, bu sunucu için ayarlanmış bir FQDN ve DNS kayıtlarınız varsa, bu dosyayı FQDN’nizden sonra adlandırabilirsiniz:
sudo nano /etc/nginx/sites-available/example.com
example.comSunucunuzun FQDN’si veya genel IP adresiyle eşleşecek şekilde güncellediğinizden emin olarak aşağıdaki kod bloğunu dosyaya ekleyin. Bu kod, Nginx’i sunucunuzun HTTP trafiğini dinleyen Kibana uygulamasına yönlendirecek şekilde yapılandırır localhost:5601. Ek olarak, Nginx’i htpasswd.usersdosyayı okuyacak ve temel kimlik doğrulaması gerektirecek şekilde yapılandırır .
Bu durumda, aşağıdakileri eklemeden önce dosyadaki tüm mevcut içeriği silin: /etc/nginx/sites-available/example.com
server {
listen 80;
server_name example.com;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}Bitirdiğinizde dosyayı kaydedin ve kapatın.
Ardından, sites-enableddizine sembolik bir bağlantı oluşturarak yeni yapılandırmayı etkinleştirin . Nginx ön koşulunda aynı ada sahip bir sunucu blok dosyası oluşturduysanız, bu komutu çalıştırmanıza gerek yoktur:
sudo ln -s /etc/nginx/sites-available/example.com /etc/nginx/sites-enabled/example.com
Ardından, söz dizimi hataları için yapılandırmayı kontrol edin:
sudo nginx -t
Çıktınızda herhangi bir hata bildirilirse, geri dönün ve yapılandırma dosyanıza yerleştirdiğiniz içeriğin doğru şekilde eklenip eklenmediğini iki kez kontrol edin. syntax is okÇıktıda gördüğünüzde devam edin ve Nginx hizmetini yeniden başlatın:
sudo systemctl restart nginx
İlk sunucu kurulum kılavuzunu takip ettiyseniz, bir UFW güvenlik duvarının etkinleştirilmiş olması gerekir. Nginx’e bağlantılara izin vermek için, kuralları yazarak ayarlayabiliriz:
sudo ufw allow 'Nginx Full'
Kibana’ya artık FQDN’niz veya Elastic Stack sunucunuzun genel IP adresi üzerinden erişebilirsiniz. Aşağıdaki adrese gidip istendiğinde oturum açma bilgilerinizi girerek Kibana sunucusunun durum sayfasını kontrol edebilirsiniz:
http://your_server_ip/statusBu durum sayfası, sunucunun kaynak kullanımı hakkındaki bilgileri görüntüler ve kurulu eklentileri listeler.
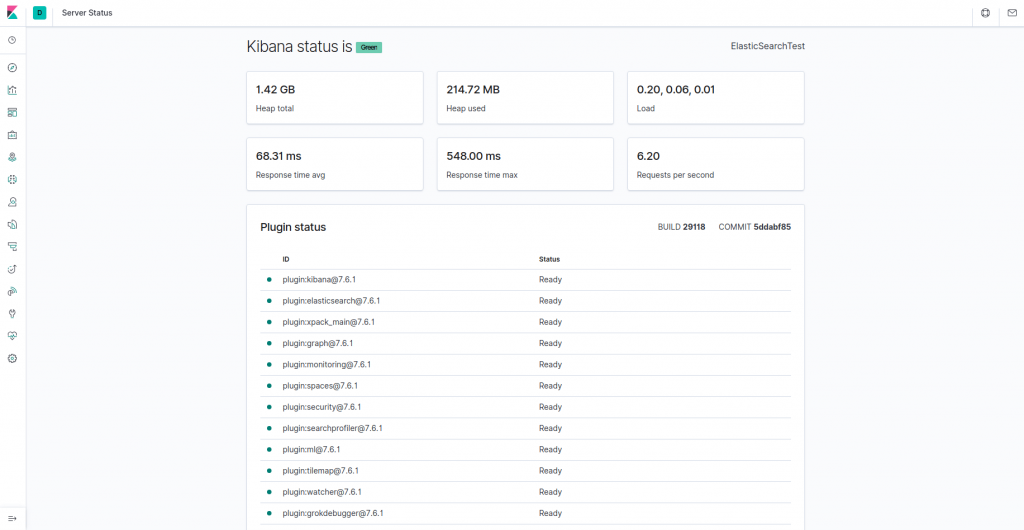
Not : Önkoşullar bölümünde belirtildiği gibi, sunucunuzda SSL / TLS’yi etkinleştirmeniz önerilir.
Artık Kibana panosu yapılandırıldığına göre, bir sonraki bileşeni kuralım: Logstash.
Adım 3 – Logstash’ı Kurmak ve Yapılandırmak
Beats’in verileri doğrudan Elasticsearch veritabanına göndermesi mümkün olsa da, verileri işlemek için Logstash’ı kullanmanızı öneririz. Bu, farklı kaynaklardan veri toplamanıza, bunları ortak bir biçime dönüştürmenize ve başka bir veritabanına aktarmanıza olanak tanır.
Logstash’ı şu komutla kurun:
sudo apt install logstash
Logstash’ı kurduktan sonra, onu yapılandırmaya devam edebilirsiniz. Logstash’ın yapılandırma dosyaları JSON biçiminde yazılır ve /etc/logstash/conf.ddizinde bulunur. Siz yapılandırırken, Logstash’ı bir uçtan veri alan, bir şekilde işleyen ve hedefine gönderen (bu durumda hedef Elasticsearch) bir ardışık düzen olarak düşünmek yararlıdır. Bir Logstash boru hattı iki gerekli elemanları, sahiptir inputve outputve isteğe bağlı bir eleman, filter. Giriş eklentileri bir kaynaktan gelen verileri tüketir, filtre eklentileri verileri işler ve çıkış eklentileri verileri bir hedefe yazar.
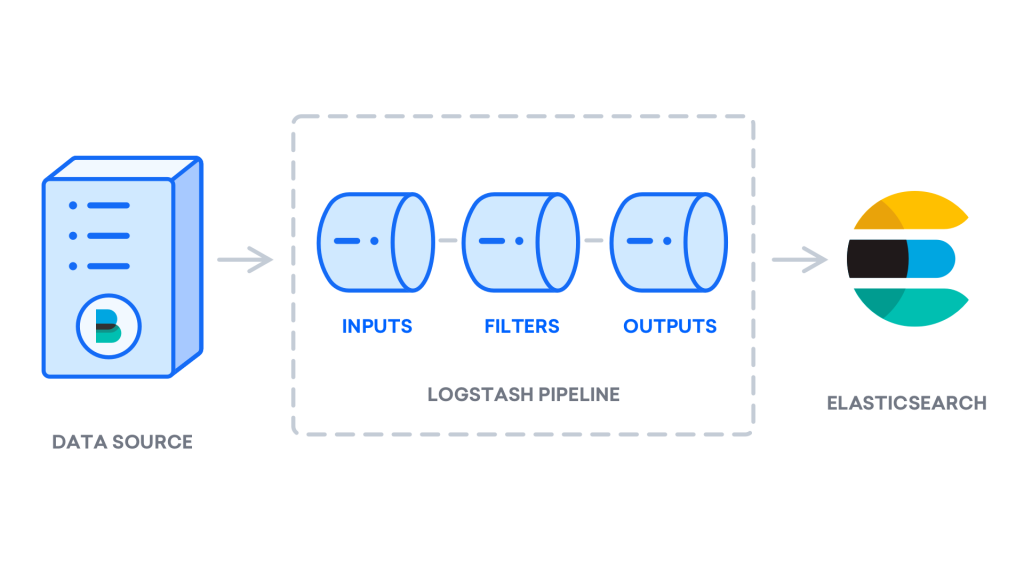
02-beats-input.confFilebeat girişinizi ayarlayacağınız adlı bir yapılandırma dosyası oluşturun :
sudo nano /etc/logstash/conf.d/02-beats-input.conf
Aşağıdaki inputyapılandırmayı ekleyin . Bu beats, TCP bağlantı noktasını dinleyecek bir girişi belirtir 5044./etc/logstash/conf.d/02-beats-input.conf /etc/logstash/conf.d/02-beats-input.conf
input {
beats {
port => 5044
}
} Dosyayı kaydedin ve kapatın. Daha sonra, adlı bir yapılandırma dosyası oluşturmak 10-syslog-filter.confbiz de olarak bilinen sistem günlükleri, için bir filtre katacak nerede, syslogs :
sudo nano /etc/logstash/conf.d/10-syslog-filter.confAşağıdaki sistem günlüğü filtre yapılandırmasını ekleyin. Bu örnek sistem günlükleri yapılandırması, resmi Elastic belgelerinden alınmıştır . Bu filtre, gelen sistem günlüklerini önceden tanımlanmış Kibana kontrol panelleri tarafından yapılandırılmış ve kullanılabilir hale getirmek için ayrıştırmak için kullanılır: /etc/logstash/conf.d/10-syslog-filter.conf
filter {
if [fileset][module] == "system" {
if [fileset][name] == "auth" {
grok {
match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] }
pattern_definitions => {
"GREEDYMULTILINE"=> "(.|\n)*"
}
remove_field => "message"
}
date {
match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
geoip {
source => "[system][auth][ssh][ip]"
target => "[system][auth][ssh][geoip]"
}
}
else if [fileset][name] == "syslog" {
grok {
match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] }
pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" }
remove_field => "message"
}
date {
match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
}filter {
if [fileset][module] == "system" {
if [fileset][name] == "auth" {
grok {
match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] }
pattern_definitions => {
"GREEDYMULTILINE"=> "(.|\n)*"
}
remove_field => "message"
}
date {
match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
geoip {
source => "[system][auth][ssh][ip]"
target => "[system][auth][ssh][geoip]"
}
}
else if [fileset][name] == "syslog" {
grok {
match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] }
pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" }
remove_field => "message"
}
date {
match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
}filter {
if [fileset][module] == "system" {
if [fileset][name] == "auth" {
grok {
match => { "message" => ["%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} %{DATA:[system][auth][ssh][method]} for (invalid user )?%{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]} port %{NUMBER:[system][auth][ssh][port]} ssh2(: %{GREEDYDATA:[system][auth][ssh][signature]})?",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: %{DATA:[system][auth][ssh][event]} user %{DATA:[system][auth][user]} from %{IPORHOST:[system][auth][ssh][ip]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sshd(?:\[%{POSINT:[system][auth][pid]}\])?: Did not receive identification string from %{IPORHOST:[system][auth][ssh][dropped_ip]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} sudo(?:\[%{POSINT:[system][auth][pid]}\])?: \s*%{DATA:[system][auth][user]} :( %{DATA:[system][auth][sudo][error]} ;)? TTY=%{DATA:[system][auth][sudo][tty]} ; PWD=%{DATA:[system][auth][sudo][pwd]} ; USER=%{DATA:[system][auth][sudo][user]} ; COMMAND=%{GREEDYDATA:[system][auth][sudo][command]}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} groupadd(?:\[%{POSINT:[system][auth][pid]}\])?: new group: name=%{DATA:system.auth.groupadd.name}, GID=%{NUMBER:system.auth.groupadd.gid}",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} useradd(?:\[%{POSINT:[system][auth][pid]}\])?: new user: name=%{DATA:[system][auth][user][add][name]}, UID=%{NUMBER:[system][auth][user][add][uid]}, GID=%{NUMBER:[system][auth][user][add][gid]}, home=%{DATA:[system][auth][user][add][home]}, shell=%{DATA:[system][auth][user][add][shell]}$",
"%{SYSLOGTIMESTAMP:[system][auth][timestamp]} %{SYSLOGHOST:[system][auth][hostname]} %{DATA:[system][auth][program]}(?:\[%{POSINT:[system][auth][pid]}\])?: %{GREEDYMULTILINE:[system][auth][message]}"] }
pattern_definitions => {
"GREEDYMULTILINE"=> "(.|\n)*"
}
remove_field => "message"
}
date {
match => [ "[system][auth][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
geoip {
source => "[system][auth][ssh][ip]"
target => "[system][auth][ssh][geoip]"
}
}
else if [fileset][name] == "syslog" {
grok {
match => { "message" => ["%{SYSLOGTIMESTAMP:[system][syslog][timestamp]} %{SYSLOGHOST:[system][syslog][hostname]} %{DATA:[system][syslog][program]}(?:\[%{POSINT:[system][syslog][pid]}\])?: %{GREEDYMULTILINE:[system][syslog][message]}"] }
pattern_definitions => { "GREEDYMULTILINE" => "(.|\n)*" }
remove_field => "message"
}
date {
match => [ "[system][syslog][timestamp]", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
}Bitirdiğinizde dosyayı kaydedin ve kapatın.
Son olarak, şu adla bir yapılandırma dosyası oluşturun 30-elasticsearch-output.conf:
sudo nano /etc/logstash/conf.d/30-elasticsearch-output.conf Aşağıdaki outputyapılandırmayı ekleyin . Esasen, bu çıktı Logstash’ı, üzerinde çalışan Elasticsearch’teki Beats verilerini, localhost:9200kullanılan Beat’in adını taşıyan bir dizinde depolayacak şekilde yapılandırır . Bu eğiticide kullanılan Beat, Filebeat’dir: /etc/logstash/conf.d/30-elasticsearch-output.conf
output {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}Dosyayı kaydedin ve kapatın.
Filebeat girişini kullanan diğer uygulamalar için filtreler eklemek istiyorsanız, dosyaları giriş ve çıkış yapılandırması arasında sıralanacak şekilde adlandırdığınızdan emin olun, yani dosya adları 02ve arasında iki basamaklı bir sayı ile başlamalıdır 30.
Logstash yapılandırmanızı şu komutla test edin:
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
Sözdizimi hatası yoksa çıktınız Configuration OKbirkaç saniye sonra görüntülenecektir . Bunu çıktınızda görmüyorsanız, çıktınızda görünen hataları kontrol edin ve bunları düzeltmek için yapılandırmanızı güncelleyin.
Yapılandırma testiniz başarılı olursa, yapılandırma değişikliklerini yürürlüğe koymak için Logstash’ı başlatın ve etkinleştirin:
sudo systemctl start logstash
sudo systemctl enable logstashArtık Logstash doğru çalıştığına ve tam olarak yapılandırıldığına göre, Filebeat’i kuralım.
Adım 4 – Filebeat’i Kurmak ve Yapılandırmak
Elastic Stack, çeşitli kaynaklardan veri toplamak ve bunları Logstash veya Elasticsearch’e taşımak için Beats adı verilen birkaç hafif veri göndericisini kullanır. Şu anda Elastic’te mevcut olan Beats’ler şunlardır:
- Filebeat : günlük dosyalarını toplar ve gönderir .
- Metricbeat : Sistemlerinizden ve hizmetlerinizden ölçümleri toplar.
- Packetbeat : ağ verilerini toplar ve analiz eder.
- Winlogbeat : Windows olay günlüklerini toplar.
- Auditbeat : Linux denetim çerçevesi verilerini toplar ve dosya bütünlüğünü izler.
- Heartbeat : hizmetleri, etkin araştırmayla kullanılabilirliği açısından izler.
Bu eğiticide, yerel günlükleri Elastic Stack’ımıza iletmek için Filebeat’i kullanacağız.
Filebeat’i şunu kullanarak kurun apt:
sudo apt install filebeat
Ardından, Filebeat’i Logstash’a bağlanacak şekilde yapılandırın. Burada Filebeat ile birlikte gelen örnek yapılandırma dosyasını değiştireceğiz.
Filebeat yapılandırma dosyasını açın:
sudo nano /etc/filebeat/filebeat.ymlNot: Elasticsearch’te olduğu gibi, Filebeat’in konfigürasyon dosyası YAML formatındadır. Bu, uygun girintinin çok önemli olduğu anlamına gelir, bu nedenle bu talimatlarda belirtilenle aynı sayıda boşluk kullandığınızdan emin olun.
Filebeat çok sayıda çıktıyı destekler, ancak genellikle ek işlemler için olayları doğrudan Elasticsearch’e veya Logstash’a gönderirsiniz. Bu eğiticide, Filebeat tarafından toplanan veriler üzerinde ek işlemler gerçekleştirmek için Logstash kullanacağız. Filebeat’in herhangi bir veriyi doğrudan Elasticsearch’e göndermesi gerekmeyecek, bu yüzden bu çıktıyı devre dışı bırakalım. Bunu yapmak için, output.elasticsearchbölümü bulun ve aşağıdaki satırların önüne bir ile yorum yapın #: /etc/filebeat/filebeat.yml
...
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
... Ardından output.logstashbölümü yapılandırın . Çizgiler uncomment output.logstash:ve hosts: ["localhost:5044"]kaldırarak #. Bu, 5044Filebeat’i daha önce bir Logstash girişi belirttiğimiz bağlantı noktasındaki Elastic Stack sunucunuzdaki Logstash’a bağlanacak şekilde yapılandıracaktır : /etc/filebeat/filebeat.yml
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]Dosyayı kaydedin ve kapatın.
Filebeat’in işlevselliği Filebeat modülleri ile genişletilebilir . Bu eğitimde , yaygın Linux dağıtımlarının sistem günlük kaydı hizmeti tarafından oluşturulan günlükleri toplayan ve ayrıştıran sistem modülünü kullanacağız .
Etkinleştirelim:
sudo filebeat modules enable system
Aşağıdakileri çalıştırarak etkinleştirilen ve devre dışı bırakılan modüllerin bir listesini görebilirsiniz:
sudo filebeat modules list
Aşağıdakine benzer bir liste göreceksiniz:
Output
Enabled:
system
Disabled:
apache2
auditd
elasticsearch
icinga
iis
kafka
kibana
logstash
mongodb
mysql
nginx
osquery
postgresql
redis
traefik
...........Varsayılan olarak, Filebeat, syslog ve yetkilendirme günlükleri için varsayılan yolları kullanacak şekilde yapılandırılmıştır. Bu eğitim durumunda, konfigürasyonda herhangi bir değişiklik yapmanıza gerek yoktur. Modülün parametrelerini /etc/filebeat/modules.d/system.ymlkonfigürasyon dosyasında görebilirsiniz.
Ardından, dizin şablonunu Elasticsearch’e yükleyin. Bir Elasticsearch indeksi , benzer özelliklere sahip bir belge koleksiyonudur. Dizinler, içinde çeşitli işlemler gerçekleştirirken dizine atıfta bulunmak için kullanılan bir adla tanımlanır. Yeni bir dizin oluşturulduğunda dizin şablonu otomatik olarak uygulanacaktır.
Şablonu yüklemek için aşağıdaki komutu kullanın:
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'
Output
Loaded index templateFilebeat, Filebeat verilerini Kibana’da görselleştirmenize olanak tanıyan örnek Kibana kontrol panelleriyle birlikte gelir. Gösterge tablolarını kullanmadan önce, dizin modelini oluşturmanız ve gösterge tablolarını Kibana’ya yüklemeniz gerekir.
Gösterge tabloları yüklenirken Filebeat, sürüm bilgilerini kontrol etmek için Elasticsearch’e bağlanır. Logstash etkinleştirildiğinde gösterge tablolarını yüklemek için Logstash çıktısını devre dışı bırakmanız ve Elasticsearch çıktısını etkinleştirmeniz gerekir:
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601
Şuna benzer bir çıktı göreceksiniz:
Output
2018-09-10T08:39:15.844Z INFO instance/beat.go:273 Setup Beat: filebeat; Version: 7.6.1
2018-09-10T08:39:15.845Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
2018-09-10T08:39:15.845Z INFO pipeline/module.go:98 Beat name: elk
2018-09-10T08:39:15.845Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
2018-09-10T08:39:15.849Z INFO elasticsearch/client.go:708 Connected to Elasticsearch version 7.6.1
2018-09-10T08:39:15.856Z INFO template/load.go:129 Template already exists and will not be overwritten.
Loaded index template
Loading dashboards (Kibana must be running and reachable)
2018-09-10T08:39:15.857Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
2018-09-10T08:39:15.865Z INFO elasticsearch/client.go:708 Connected to Elasticsearch version 7.6.1
2018-09-10T08:39:15.865Z INFO kibana/client.go:113 Kibana url: http://localhost:5601
2018-09-10T08:39:45.357Z INFO instance/beat.go:659 Kibana dashboards successfully loaded.
Loaded dashboards
2018-09-10T08:39:45.358Z INFO elasticsearch/client.go:163 Elasticsearch url: http://localhost:9200
2018-09-10T08:39:45.361Z INFO elasticsearch/client.go:708 Connected to Elasticsearch version 7.6.1
2018-09-10T08:39:45.361Z INFO kibana/client.go:113 Kibana url: http://localhost:5601
2018-09-10T08:39:45.455Z WARN fileset/modules.go:388 X-Pack Machine Learning is not enabled
Loaded machine learning job configurationsArtık Filebeat’i başlatabilir ve etkinleştirebilirsiniz:
sudo systemctl start filebeat
sudo systemctl enable filebeatElastic Stack’inizi doğru bir şekilde kurduysanız, Filebeat sistem günlüğünüzü ve yetkilendirme günlüklerinizi Logstash’a göndermeye başlayacak ve ardından bu verileri Elasticsearch’e yükleyecektir.
Elasticsearch’ün gerçekten bu verileri aldığını doğrulamak için, Filebeat dizinini şu komutla sorgulayın:
curl -XGET 'http://localhost:9200/filebeat-*/_search?pretty'
Şuna benzer bir çıktı göreceksiniz:
Output
...
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 10000,
"relation" : "gte"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "filebeat-7.6.1-2020.03.22-000001",
"_type" : "_doc",
"_id" : "_vafAnEB9n8Ibpfym4VS",
"_score" : 1.0,
"_source" : {
"agent" : {
"hostname" : "ElasticSearch",
"id" : "ee9d1a5d-75a7-4283-a126-ee90c1455173",
"type" : "filebeat",
"ephemeral_id" : "b927d9fb-500a-43ab-a20c-598d55c080ac",
"version" : "7.6.1"
},
"process" : {
"name" : "kernel"
},
"log" : {
"file" : {
"path" : "/var/log/syslog"
},
"offset" : 97048
},
"fileset" : {
"name" : "syslog"
},
...Çıktınız toplam 0 isabet gösteriyorsa, Elasticsearch aradığınız dizinin altına herhangi bir günlük yüklemiyordur ve hatalar için kurulumunuzu gözden geçirmeniz gerekecektir. Beklenen çıktıyı aldıysanız, Kibana’nın bazı gösterge tablolarında nasıl gezineceğimizi göreceğimiz bir sonraki adıma geçin.
Adım 5 – Kibana Kontrol Panellerini Keşfetme
Daha önce kurduğumuz web arayüzü Kibana’ya bakalım.
Bir web tarayıcısında, Elastic Stack sunucunuzun FQDN’sine veya genel IP adresine gidin. 2. Adımda tanımladığınız oturum açma bilgilerini girdikten sonra, Kibana ana sayfasını göreceksiniz:
Sol taraftaki gezinme çubuğundaki Keşfet bağlantısını tıklayın . On Keşfedin sayfasında, önceden tanımlanmış seçmek filebeat- Filebeat verileri görmek için * indeks deseni. Varsayılan olarak, bu size son 15 dakikanın tüm günlük verilerini gösterecektir. Günlük olayları içeren bir histogram ve aşağıda bazı günlük mesajları göreceksiniz:
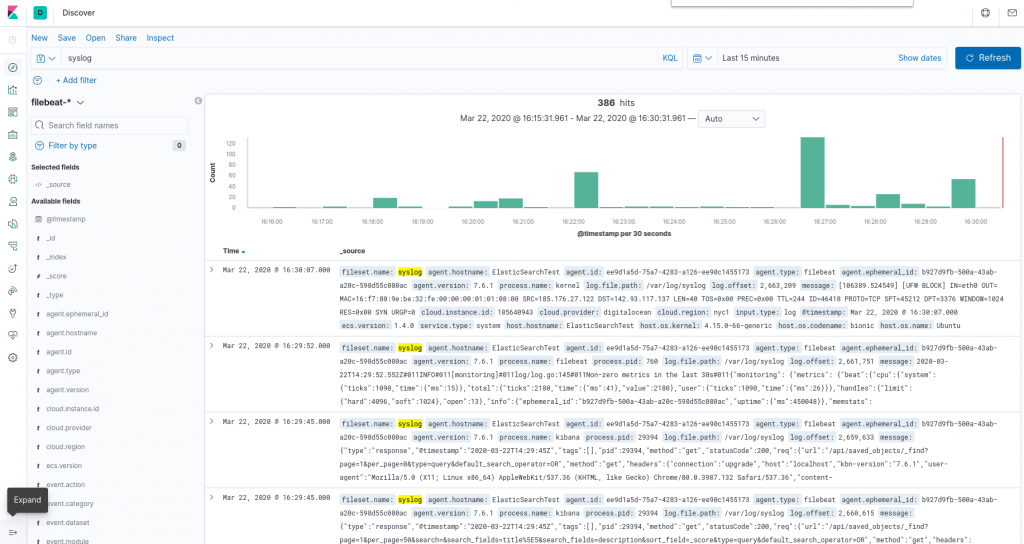
Burada, günlüklerinizi arayabilir ve göz atabilir ve ayrıca kontrol panelinizi özelleştirebilirsiniz. Ancak bu noktada, orada çok fazla şey olmayacak çünkü yalnızca Elastic Stack sunucunuzdan sistem günlükleri topluyorsunuz.
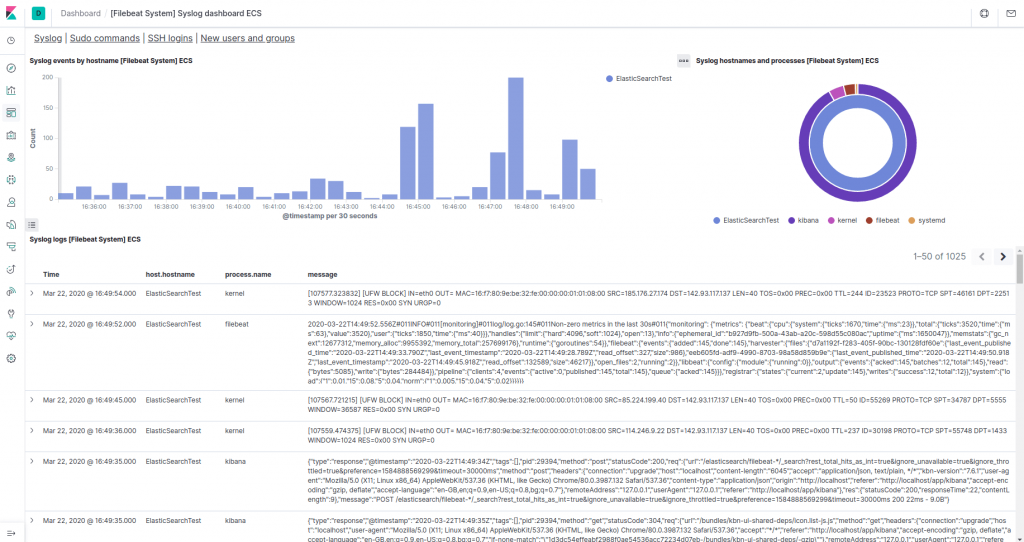
Gösterge Tablosu sayfasına gitmek ve Filebeat Sistemi gösterge tablolarını aramak için sol taraftaki paneli kullanın . Oraya vardığınızda, Filebeat systemmodülüyle birlikte gelen örnek panoları arayabilirsiniz .
Örneğin, sistem günlüğü mesajlarınıza göre ayrıntılı istatistikleri görüntüleyebilirsiniz:
sudoKomutu hangi kullanıcıların ne zaman kullandığını da görüntüleyebilirsiniz :
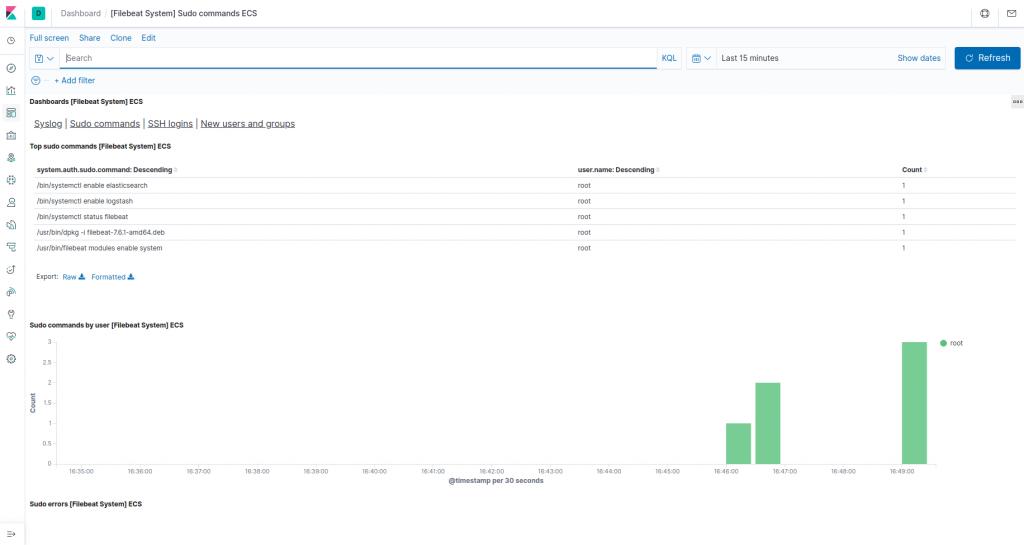
Kibana, grafik oluşturma ve filtreleme gibi başka birçok özelliğe sahiptir, bu yüzden keşfetmekten çekinmeyin.
Sonuç
Bu eğiticide, sistem günlüklerini toplamak ve analiz etmek için Elastic Stack’ı nasıl kuracağınızı ve yapılandıracağınızı öğrendiniz. Beats kullanarak Logstash’a hemen hemen her türden günlük veya dizine eklenmiş veri gönderebileceğinizi unutmayın , ancak veriler bir Logstash filtresi ile ayrıştırılıp yapılandırılırsa daha da kullanışlı hale gelir çünkü bu, verileri okunabilen tutarlı bir biçime dönüştürür. Elasticsearch ile kolayca.



